nenupy.io.tf
Time-frequency data

|
Class to read UnDySPuTeD Time-Frequency files (.spectra extension). |
|
Class to handle a single task/operation designed to be applied to time-frequency data. |
|
Class to manage the series of tasks designed to be applied to time-frequency data. |
- class nenupy.io.tf.Spectra(filename, check_missing_data=True)[source]
Bases:
objectClass to read UnDySPuTeD Time-Frequency files (.spectra extension).
- Parameters:
filename (
str) – Path to the UnDySPuTeD file to read.- Raises:
ValueError – If the
filenameextension differs from ‘.spectra’.
Notes
Added in version 2.6.0.
- property frequency_max
Highest recorded frequency. This value is defined at the channel granularity, i.e. it corresponds to the last channel of the highest sub-band.
Example
>>> from nenupy.io.tf import Spectra >>> sp = Spectra("/my/file.spectra") >>> sp.frequency_max 57.421875 MHz
- Type:
- property frequency_min
Lowest recorded frequency. This value is defined at the channel granularity, i.e. it corresponds to the first channel of the lowest sub-band.
Example
>>> from nenupy.io.tf import Spectra >>> sp = Spectra("/my/file.spectra") >>> sp.frequency_min 19.921875 MHz
- Type:
- get(file_name=None, **pipeline_kwargs)[source]
Perform data selection and pipeline computation.
- Parameters:
file_name (
str, default:None) – If different thanNone(default value), name of the HDF5 file (extension ‘.hdf5’) to create and store the result.**pipeline_kwargs – Any
pipelineparameter passed as keyword argument from the list below. Changes applied here are not kept once the method has resolved.tmin (
strorTime, default: \({\rm min}(t)\)) – Lower edge of time selection, can either be given as aTimeobject or an ISOT/ISO string.tmax (
strorTime, default: \({\rm max}(t)\)) – Upper edge of time selection, can either be given as anTimeobject or an ISOT/ISO string.fmin (
floatorQuantity, default: \({\rm min}(\nu)\)) – Lower frequency boundary selection, can either be given as aQuantityobject or float (assumed to be in MHz in that case).fmax (
floatorQuantity, default: \({\rm max}(\nu)\)) – Higher frequency boundary selection, can either be given as aQuantityobject or float (assumed to be in MHz in that case).beam (
int, default: first recorded beam) – Beam selection, a single integer corresponding to the index of a recorded numerical beam is expected.dispersion_measure (
floatorQuantity, default:None) – Enable de-dispersion of the data by this Dispersion Measure. Note that thede_disperse()task should be present in the planned pipeline (pipeline). It can either be provided as aQuantityobject or a float (assumed to be in \({\rm pc}\,{\rm cm}^{-3}\) in that case).rotation_measure (
floatorQuantity, default:None) – Enable the correction of the Faraday rotation using this Rotation Measure. Note that thecorrect_faraday_rotation()task should be present in the planned pipeline (pipeline). It can either be provided as aQuantityobject or a float (assumed to be in \({\rm rad}\,{\rm m}^{-2}\) in that case).rebin_dt (
floatorQuantity, default:None) – Desired rebinning time resolution, can either be given as aQuantityobject or a float (assumed to be in sec in that case). Note that thetime_rebin()task should be present in the planned pipeline (pipeline).rebin_df (
floatorQuantity, default:None) – Desired rebinning frequency resolution, can either be given as aQuantityobject or float (assumed to be in kHz in that case). Note that thefrequency_rebin()task should be present in the planned pipeline (pipeline).remove_channels (
listorndarray, default:None) – List of subband channels to remove, e.g.remove_channels=[0,1,-1]would remove the first, second (low-freq) and last channels from each subband. Note that theremove_channels()task should be present in the planned pipeline (pipeline).dreambeam_skycoord (
SkyCoord, default:None) – Tracked celestial coordinates used during DreamBeam correction (along with'dreambeam_dt'and'dreambeam_parallactic'), aSkyCoordobject is expected. Note that thecorrect_polarization()task should be present in the planned pipeline (pipeline).dreambeam_dt (
floatorQuantity, default:None) –DreamBeam correction time resolution (along with
'dreambeam_skycoord'and'dreambeam_parallactic'), aQuantityobject or a float (assumed in seconds) are expected. Note that thecorrect_polarization()task should be present in the planned pipeline (pipeline).dreambeam_parallactic (
bool, default:True) –DreamBeam parallactic angle correction (along with
'dreambeam_skycoord'and'dreambeam_dt'), a boolean is expected. Note that thecorrect_polarization()task should be present in the planned pipeline (pipeline).stokes (
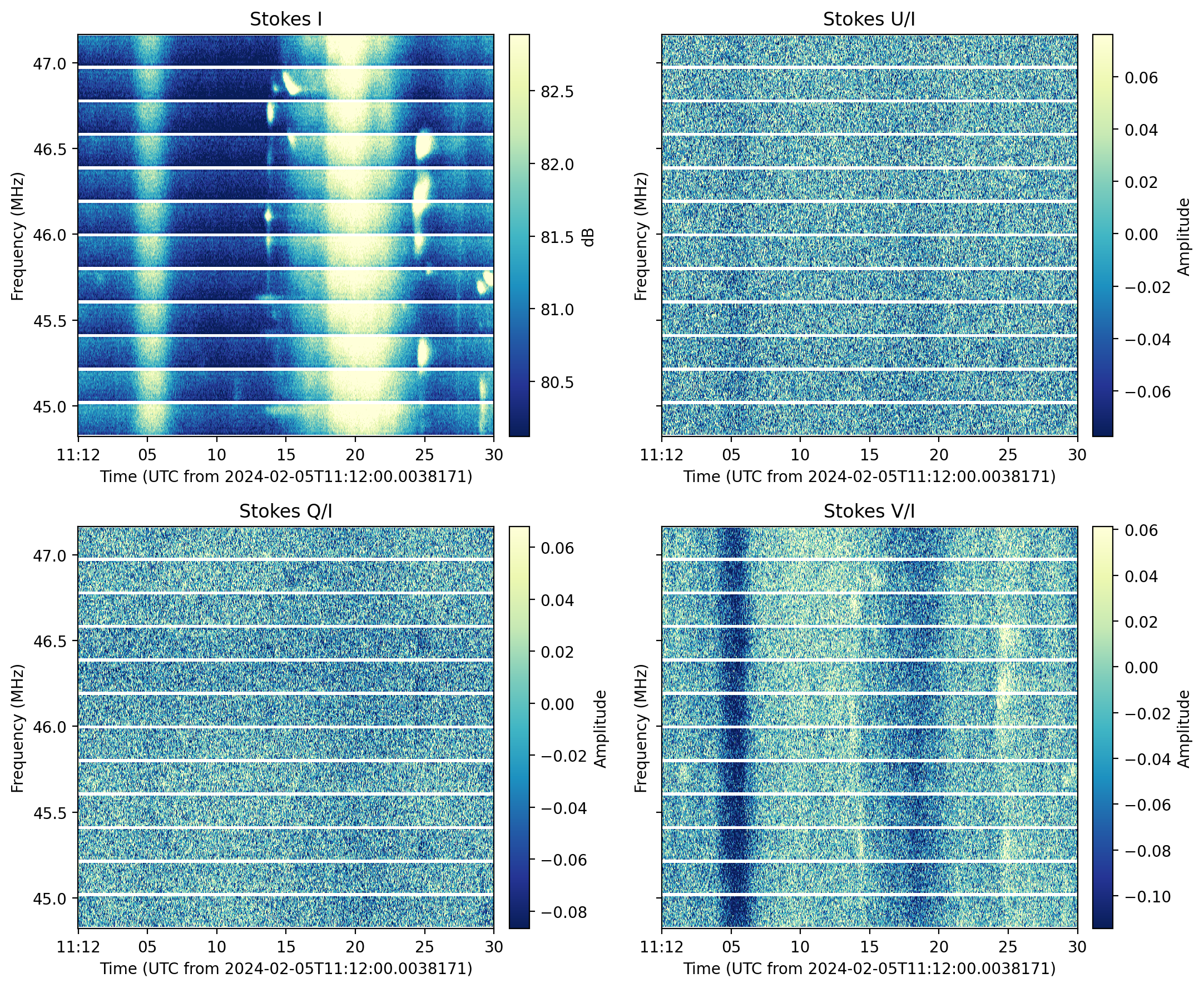
strorlist[str], default:"I") – Stokes parameter selection, can either be given as a string or a list of strings, e.g.['I', 'Q', 'V/I']. Note that theget_stokes()task should be present in the planned pipeline (pipeline).ignore_volume_warning (
bool, default:False) – Ignore or not (default value) the limit regarding output data volume.
- Returns:
Processed data selection.
- Return type:
Examples
>>> from nenupy.io.tf import Spectra >>> sp = Spectra("/my/file.spectra") >>> result = sp.get(tmin="2024-01-01 12:00:00", tmax="2024-01-01 13:00:00")
- info()[source]
Display informations about the file.
Example
>>> from nenupy.io.tf import Spectra >>> sp = Spectra("/my/file.spectra") >>> sp.info() filename: /my/file.spectra time_min: 2023-05-27T08:39:02.0000050 time_max: 2023-05-27T08:59:34.2445748 dt: 20.97152 ms frequency_min: 19.921875 MHz frequency_max: 57.421875 MHz df: 3.0517578125 kHz Available beam indices: ['0']
- select_raw_data(tmin_unix, tmax_unix, fmin_hz, fmax_hz, beam)[source]
Select a subset from a time-frequency NenuFAR dataset.
- Parameters:
- Raises:
KeyError – If
beamdoes not correspond to any recorded value.- Returns:
Length-3 tuple, respectively containing the frequency in Hz and the time in unix as
numpyarrays, then the selected dataset. The latter should be shaped as (time, frequency, 2, 2) where the last two dimensions are the Jones matrix of the electric field cross correlations. If the chosen time arguments lead to an empty selection, a length-3 tuple ofNoneis returned. If the frequency selection is off, the closest subband is returned.- Return type:
Notes
Added in version 2.6.0.
Example
>>> import nenupy >>> sp = Spectra("/my/file.spectra") >>> data = sp.select_raw_data( tmin_unix=1685176742.000005, tmax_unix=1685176802.000005, fmin_hz=21e6, fmax_hz=22e6, beam=0 ) >>> data[0].shape, data[1].shape, data[2].shape ((384,), (2856,), (2856, 384, 2, 2))
- property time_max
Final time of the data content.
Example
>>> from nenupy.io.tf import Spectra >>> sp = Spectra("/my/file.spectra") >>> sp.time_max.isot '2023-05-27T08:59:34.2445748'
- Type:
- class nenupy.io.tf.TFPipeline(data_obj, *tasks)[source]
Bases:
objectClass to manage the series of tasks designed to be applied to time-frequency data.
- Parameters:
- info(return_str=False)[source]
Display the current pipeline configuration. The tasks are ordered as they will be applied. Tasks in parenthesis are not considered ‘activated’. This can happen because the task is looking for an argument in
parameterswhose value does not fulfill the requirements.- Parameters:
return_str (
bool, optional) – Return the information message as a string variable, by defaultFalse.- Returns:
If
return_stris set toTrue, the message is returned as a string variable.- Return type:
Example
>>> from nenupy.io.tf import Spectra, TFPipeline, TFTask >>> sp = Spectra("/my/file.spectra") >>> pipeline = TFPipeline(sp, TFTask.correct_bandpass(), TFTask.correct_faraday_rotation()) >>> pipeline.info() Pipeline configuration: 0 - Correct bandpass (1 - Correct faraday rotation)
- insert(operation, index)[source]
Insert a pipeline task at a given position among the list of planned tasks.
- property parameters
Attribute listing all the available parameters. Each time a
TFTaskis run, itsupdate()method is called and this parameter list is passed.- Returns:
Pipeline parameters.
- Return type:
- remove(*args)[source]
Remove a task from the list.
- Parameters:
*args (
strorint) – If an integer is found, the task indexed at the corresponding value will be removed. If a string is found, the first instance of theTFTaskwhosenamecorresponds toargwill be removed.- Raises:
TypeError – If
argscontains any item that is neitherintnorstr.
Example
>>> from nenupy.io.tf import Spectra, TFPipeline, TFTask >>> pipeline = TFPipeline( Spectra("/my/file.spectra") ) >>> pipeline.set_default() >>> pipeline.info() Pipeline configuration: 0 - Correct bandpass (1 - Remove subband channels) (2 - Rebin in time) (3 - Rebin in frequency) 4 - Compute Stokes parameters >>> pipeline.remove("Rebin in frequency", 1) >>> pipeline.info() Pipeline configuration: 0 - Correct bandpass (1 - Rebin in time) 2 - Compute Stokes parameters
- run(time_unix, frequency_hz, data)[source]
Run all the tasks registered in the pipeline.
- Parameters:
time_unix (
ndarray) – Original array of time samples in Unix format (should match the first dimension ofdata).frequency_hz (
ndarray) – Original array of frequency samples in Hz (should match the second dimension ofdata)data (
Array) – Original data array, its shape should be(time, frequency, 2, 2).
- Returns:
Returns quantities equivalent to the inputs. The sizes of
time_unixandfrequency_hzmay have change (if rebinning steps have been included in the pipeline for instance). The first two dimensions ofdatashould still match those oftime_unixandfrequency_hz. The last dimensions depend on the polarization computation.- Return type:
- set_default()[source]
Set the default pipeline. The list of tasks is:
Bandpass correction (
correct_bandpass())Remove channels at the subband edges (
remove_channels())Rebin the data in time (
time_rebin())Rebin the data in frequency (
frequency_rebin())Convert the data to Stokes parameters (
get_stokes())
- class nenupy.io.tf.TFTask(name, func, args_to_update=[], repeatable=False)[source]
Bases:
objectClass to handle a single task/operation designed to be applied to time-frequency data.
- Parameters:
name (str) – Name of the task (it can be anything).
func (callable) – Function that applies the operation to the data.
args_to_update (list[str]) – List of parameter names that are extracted from
TFPipelineParametersand are required byfunc. These parameters will be updated by their current values (stored inTFPipelineParameters) prior to running the task.
Pre-defined Tasks
TFTaskto correct for the sub-band bandpass response.TFTaskto flatten each sub-band bandpass.TFTaskcallingremove_channels_per_subband()to set a list of sub-band channels toNaNvalues._summary_
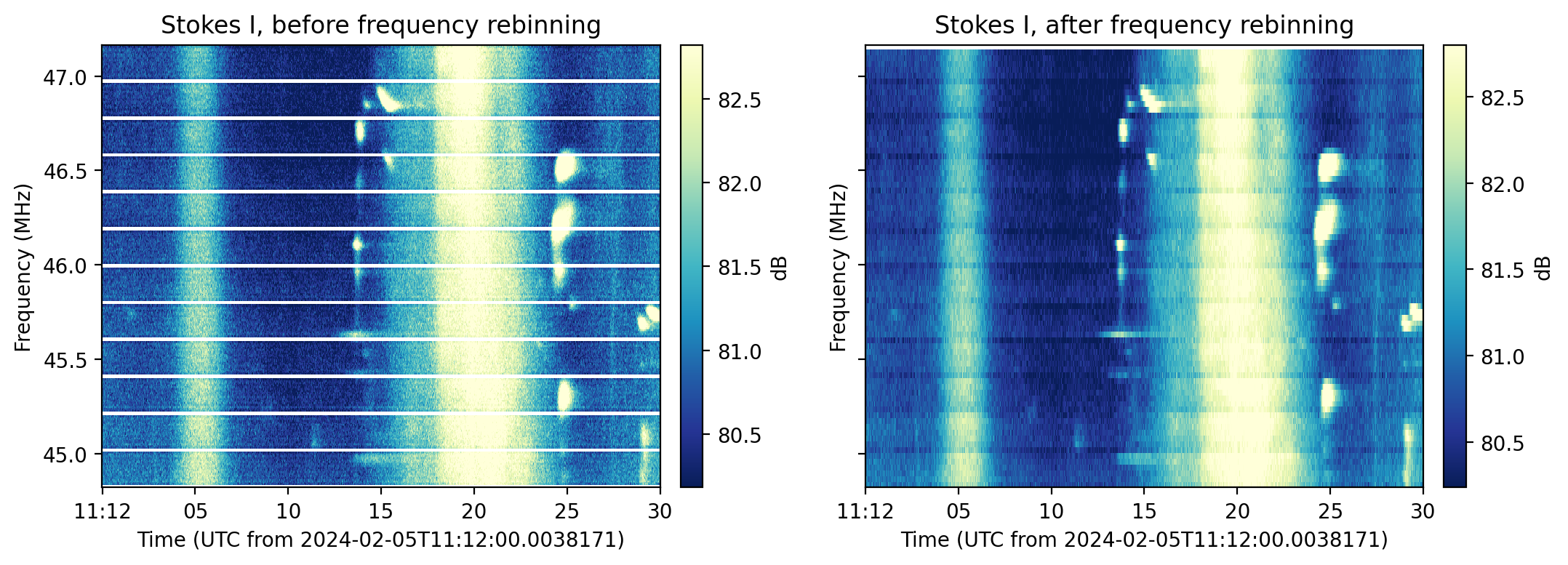
TFTaskcallingde_faraday_data()to correct for Faraday rotation for a given'rotation_measure'set inparameters.TFTaskcallingde_disperse_array()to de-disperse the data using the'dispersion_measure'set inparameters.TFTaskto re-bin the data in time._summary_
_summary_
Methods
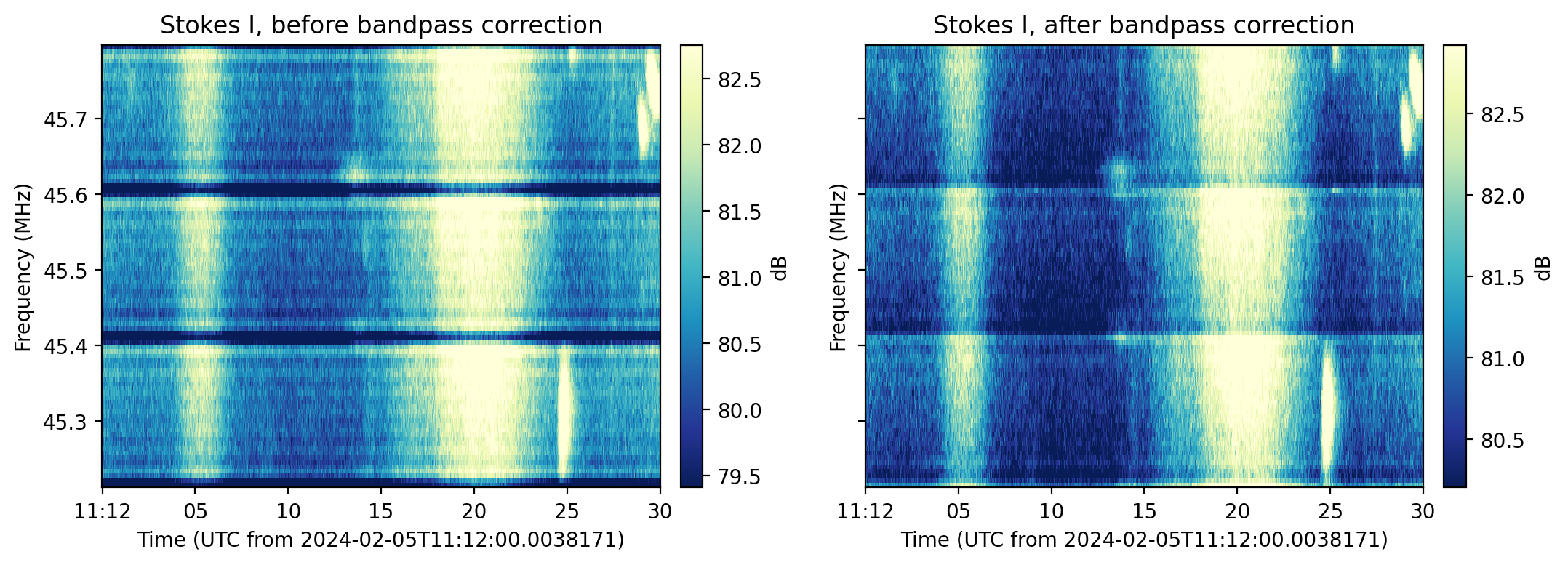
update(parameters)- classmethod correct_bandpass()[source]
TFTaskto correct for the sub-band bandpass response.A Poly-Phase Filter is involved in the NenuFAR data acquisition pipeline to split the data stream into sub-bands. The combination of the filter shape and a Fourier transform results in a non-flat response across each sub-band. This
TFTaskcalls thecorrect_bandpass()function.Example
>>> from nenupy.io.tf import Spectra, TFTask, TFPipeline >>> sp = Spectra("/my/file.spectra") >>> sp.pipeline = TFPipeline(sp, TFTask.correct_bandpass()) >>> data = sp.get(...)
- classmethod correct_faraday_rotation()[source]
TFTaskcallingde_faraday_data()to correct for Faraday rotation for a given'rotation_measure'set inparameters.
- classmethod de_disperse()[source]
TFTaskcallingde_disperse_array()to de-disperse the data using the'dispersion_measure'set inparameters.Warning
Due to the configuration of the underlying
Array, itsdask.array.Array.compute()method has to be applied priori to de-dispersing the data. Therefore, a potential huge data volume may be computed at once. By default, a security exception is raised to prevent computing a too large data set. To bypass this limit, set'ignore_volume_warning'ofparameterstoTrue.
- classmethod flatten_subband()[source]
TFTaskto flatten each sub-band bandpass. Based on the temporal median over each suband, a linear correction is applied to flatten the signal. ThisTFTaskcalls theflatten_subband()function.Example
>>> from nenupy.io.tf import Spectra, TFTask, TFPipeline >>> sp = Spectra("/my/file.spectra") >>> sp.pipeline = TFPipeline(sp, TFTask.flatten_subband()) >>> data = sp.get(...)
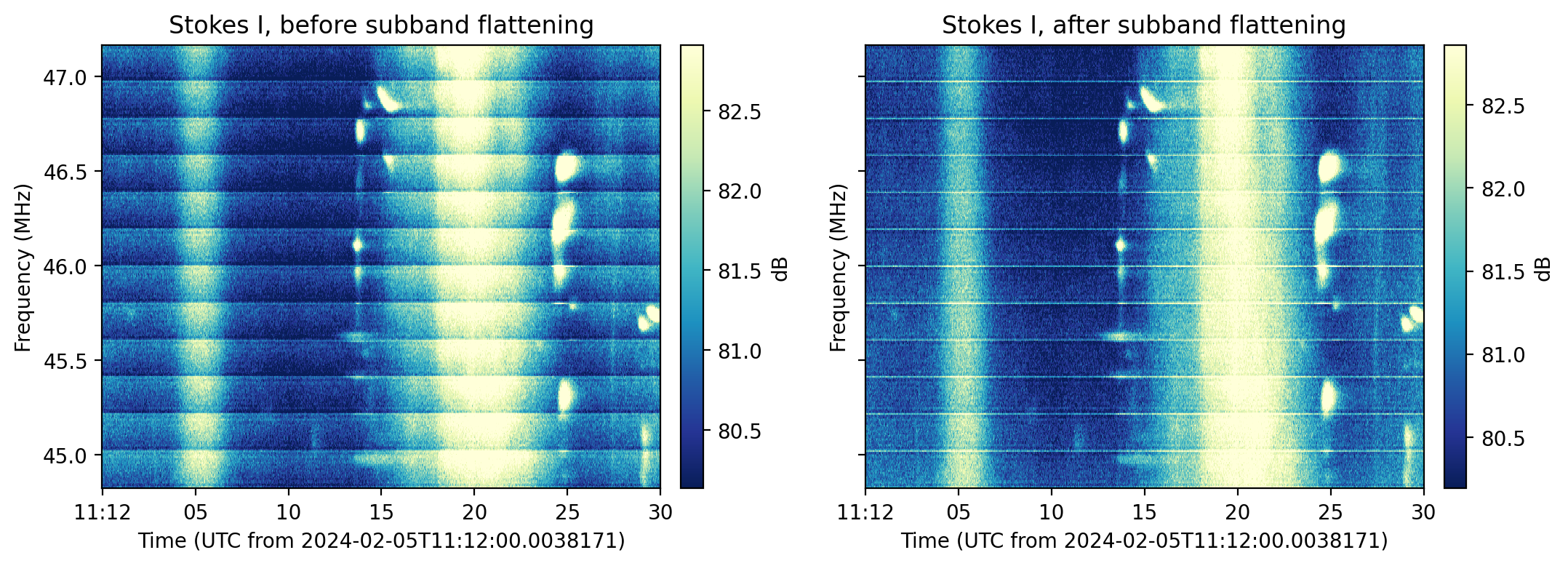
Warning
This correction assumes that the signal’s spectrum could be considered flat at the sub-band resolution. The method is not recommended for data other than Stokes I.
- classmethod remove_channels()[source]
TFTaskcallingremove_channels_per_subband()to set a list of sub-band channels toNaNvalues.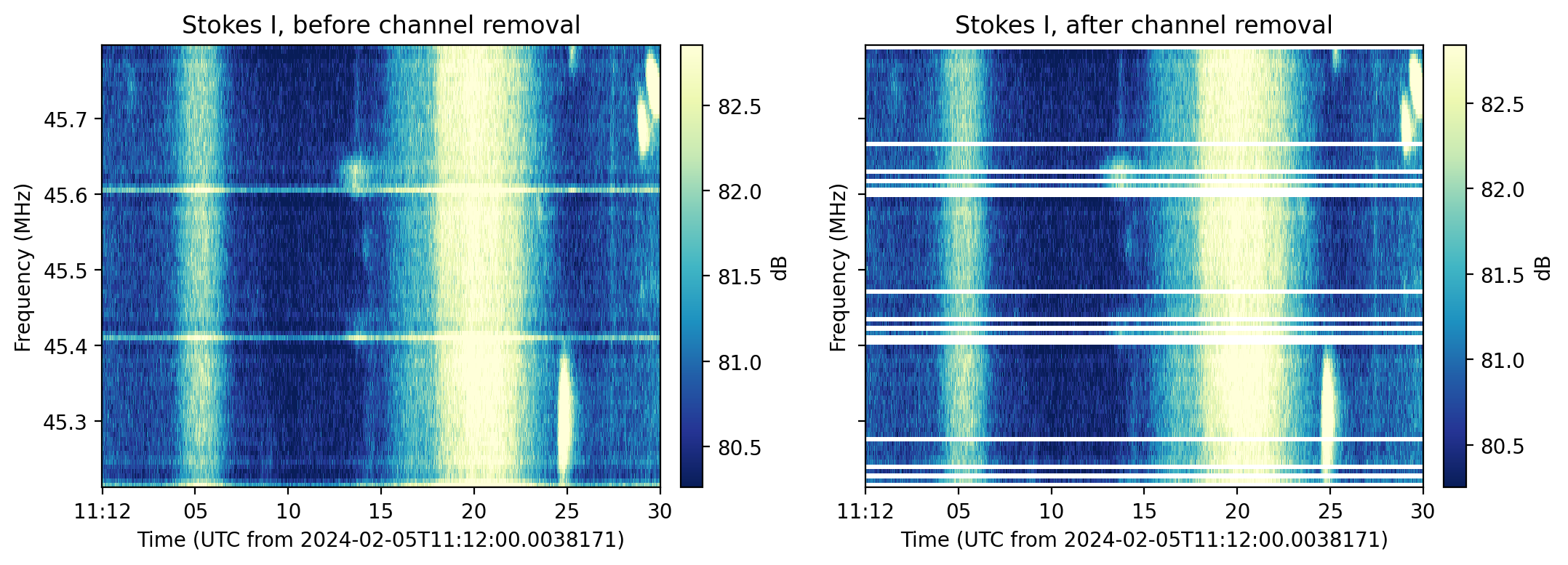
- classmethod time_rebin()[source]
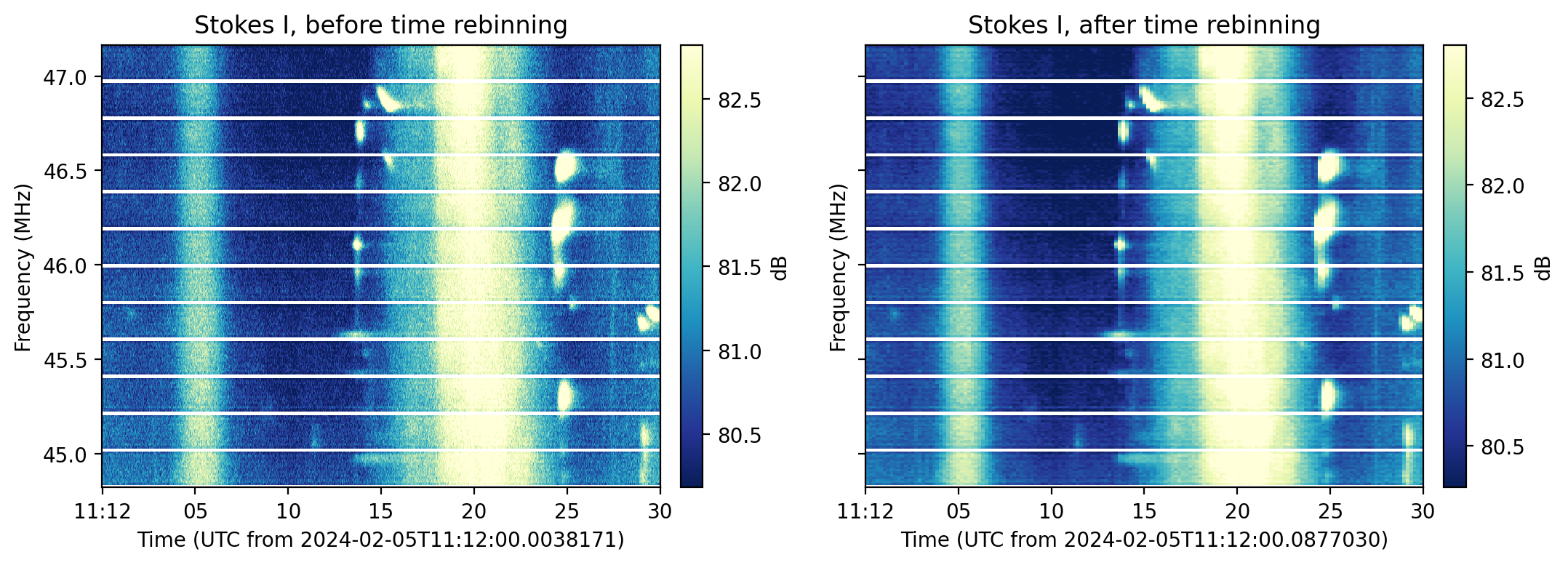
TFTaskto re-bin the data in time. The targetted time resolution is defined by the'rebin_dt'argument, set inparameters. ThisTFTaskcalls therebin_along_dimension()function.Example
>>> from nenupy.io.tf import Spectra, TFTask, TFPipeline >>> import astropy.units as u >>> sp = Spectra("/my/file.spectra") >>> sp.pipeline = TFPipeline(sp, TFTask.time_rebin())
Then, either perform a one_time application of the
rebin_dtparameter (that is forgotten after theget()call):>>> data = sp.get(..., rebin_dt=0.2*u.s,...)
Or, set it for further usage:
>>> sp.pipeline.parameters["rebin_dt"] = 0.2*u.s >>> data = sp.get(...)